When designing the Occupant Classification system for automotive passenger seats, we had to test *thousands* of people to correlate the weight plus weight distribution of children, car seats (empty and occupied), 5th percentile females (105 pounds, approximately the lower limit of where you want an air bag to deploy in a crash), average size adults...every size person that might be in a vehicle's passenger seat. We recruited all over the place--employees, their spouses, their kids, a modeling school, a cheerleader camp (to get those 5th % females)...
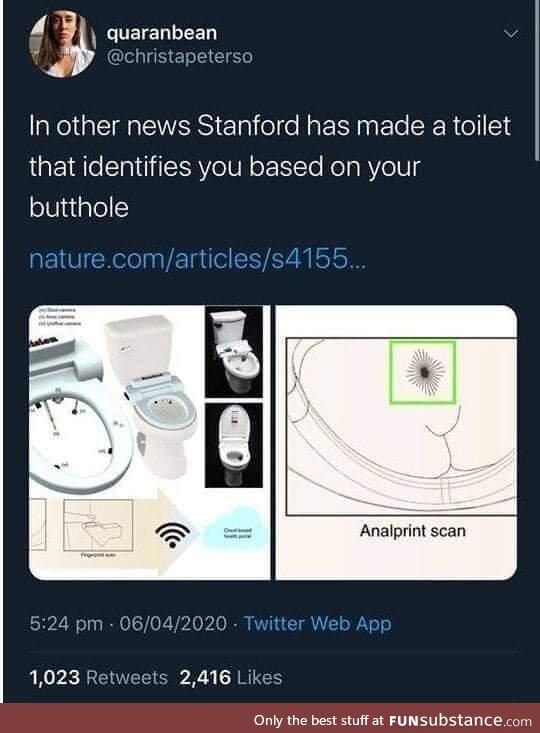
Now, imagine the effort to get enough data to develop and calibrate an algorithm that correlates butthole size/shape/characteristics to gender. Statistically, what sample size do you need for high confidence in the algorithm's determination?
Statistical nuance: Assumption--the input data is representative of user data.
Reality--the input data is representative of people willing to undergo an ass-scan.
Your comment and the original topic reminded me of the time an Ophthalmologist's office had a sign offering "Free Rectal Scans."
Maybe a victim of spell check at the sign printer?










*pun intended*
Now, imagine the effort to get enough data to develop and calibrate an algorithm that correlates butthole size/shape/characteristics to gender. Statistically, what sample size do you need for high confidence in the algorithm's determination?
Statistical nuance: Assumption--the input data is representative of user data.
Reality--the input data is representative of people willing to undergo an ass-scan.
Maybe a victim of spell check at the sign printer?